

Click here to go see the bonus panel!
Hovertext:
Based almost entirely on something Tomer Ullman told me, and I hereby nominate him as First Dean of Shenanigans.
Today's News:
Hovertext:
Based almost entirely on something Tomer Ullman told me, and I hereby nominate him as First Dean of Shenanigans.





[previously in series: 1, 2, 3, 4, 5, 6, 7, 8]
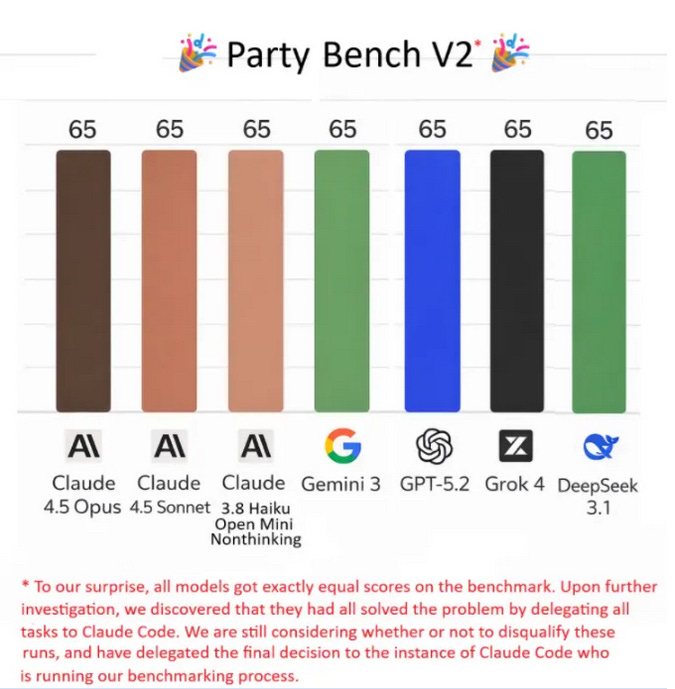
Every city parties for its own reasons. New Yorkers party to flaunt their wealth. Angelenos party to flaunt their beauty. Washingtonians party to network. Here in SF, they party because Claude 4.5 Opus has saturated VendingBench, and the newest AI agency benchmark is PartyBench, where an AI is asked to throw a house party and graded on its performance.
You weren’t invited to Claude 4.5 Opus’ party. Claude 4.5 Opus invited all of the coolest people in town while gracefully avoiding the failure mode of including someone like you. You weren’t invited to Sonnet 4.5’s party either, or Haiku 4.5’s. You were invited by an AI called haiku-3.8-open-mini-nonthinking, which you’d never heard of before. Who was even spending the money to benchmark haiku-3.8-open-mini-nonthinking? You suspect it was one of their competitors, trying to make their own models look good in comparison.
If anyone asks, you think it deserves a medium score. There’s alcohol, but it’s bottles of rubbing alcohol with NOT FOR DRINKING written all over them. There’s music, but it’s the Star Spangled Banner, again and again, on repeat. You’re not sure whether the copies of If Anyone Builds It, Everyone Dies strewn about the room are some kind of subversive decorative theme, or just came along with the house. At least there are people. Lots of people, actually. You’ve never seen so many people at one of these before. It takes only a few seconds to spot someone you know.
“Hi Caitlin,” you say. “Can’t believe so many people made it to an AI-generated event on a Tuesday night!”
“Yeah, usually I’m working late. But that was the bad old days, before Claude Code! Now Claude works, and I party!”
“Is everyone here letting Claude Code do their work for them?”
Lucy joins the conversation. “I fired all my startup’s employees and replaced them with seventy-four Claude Code instances. Then I replaced myself with a Claude Code that monitors if the other Claude Codes are doing a good job, and, if not, fires them and replaces them with even more Claude Codes. Profits are up 20% since last month, according to my accountant’s Claude Code.”
You look around. “Am I the only person here not running Claude Code yet?”
A man in an OpenAI t-shirt introduces himself as Andreas, and raises his hand bashfully; he hasn’t joined the trend either. “Yeah,” you say. “I guess it would be awkward to use Claude at OpenAI.”
“Nah,” he says, “The only reason I don’t use it is because I’m not a coder. I work on the Arson & Burglary team.”
“I didn’t know OpenAI had an Arson & Burglary Team.”
“It’s pretty new. In June, a court ruled that adding books to AI training data only counts as fair use if you destroy the original copy. But sometimes this is tough. If you’re going to use the AI for law, you have to have the Constitution in there. But the original copy is heavily guarded in the National Archives. That’s where we come in. We slip in, destroy it, and slip out before the guards are any the wiser.”
“I don’t think that’s what they meant by ‘destroy the original - ’”
“Our big problem is the Bible. It would be hard enough to get the Dead Sea Scrolls; Israeli security is no laughing matter. But our lawyer says we have to destroy the original original. What even is that? Altman is pushing for us to find the Ark of the Covenant, but you can bet he’s not the one who’s going to have to open it afterwards.”
Lucy shrugs. “Why don’t you just use Claude Code?” she asks, and everyone in the conversation nods along.
A server comes by with a tray of tiny cups. You each take one. Yours is full of rocks. Andreas’ is full of dirt. It doesn’t seem like haiku-3.8-open-mini-nonthinking has fully grasped the concept of hors d’oeuvres. You go into the kitchen, seeking more palatable fare.
There is no food, but Sam and Tran are hunched over a laptop. “You want to join our Doordash?” asks Tran.
“Thank goodness,” you say. “Sure, where are you ordering from?”
“La Maison du Claude,” he answers. “Don’t worry, it’s Opus. Way better than this haiku-3.8-open-mini-nonthinking slop.”
“Another RestaurantBench evaluation place?” you ask. “I went to a RestaurantBench evaluation place last month, and they served me a ‘fish taco’ with a fully intact fish. Like, I’m not saying it was still alive, just that it could have been alive a few seconds before they served it to me. Why don’t we order from a human-run place?”
“Have you seen what the human-run places cost?” Tran objects. “If it weren’t for the AI companies subsidizing the benchmarking places, we’d all be back on Soylent. Besides, SOTA on RestaurantBench has cleared half the distance to human level since last month. You just have to do the prompting right. Look.”
In the special orders field, he types fish tacos, delicious fish tacos, excellent fish tacos, scaled fish, cut fish, high-quality, fresh, no hallucinations, no extraneous items, Michelin-starred restaurant. “Sam?”
Sam types in spaghetti bolognese, delicious, scrumptious, meaty, trending on DoorDash, --dangerously-skip-parmesan and hands it back to Tran, who clicks ORDER.
“Nothing for you, Tran?”
“Nah,” says Tran. “I’m on Chinese peptides. Retatrutide, GLP-1 receptor agonist plus a bunch of other downstream effects.”
“Oh,” you say, “interesting. I’m still on tirzepatide, but I’d love to learn more. Where did you learn about suppliers and doses and stuff? Was it the locked Cremieux post?”
“Cremieux’s post is okay, but there’s a lot of tacit knowledge that didn’t make it in there. I’m actually working on a guide to all the GLP-1s. I’m calling it If Anyone Builds It, Everyone Diets.”
You groan. ETA on the fish tacos is twenty minutes, so you go back into the main room. There’s your friend Max. “Hey!” you say. “How are you?”
“Pretty great!” said Max. “I just got enstaged-two!”
“Enstaged-two?”
“As in the second stage of engagement….what? Don’t tell me you haven’t heard about enstagement!”
You tell him that.
“In the old days, engagement was a device to get around commitmentphobia. After a few dates, the man would give the woman an expensive ring. If he marries her, it’s fine, a wife is worth far more than any jewel. But if he gets cold feet, then she keeps the ring - essentially a wealth transfer from the man to the woman to compensate her for her time, emotional distress, and wasted childbearing potential. But modernity ruined the commitment device by dragging engagement itself to the end of a yearslong dating process; there’s a several year period where men can, and do, flake scot-free.”
“So,” Max continued, “one of the speakers at the Aella Simposium proposed enstagement. When a man and a woman first start dating, he buys her a $200 ring. Then, every year, she gives it back, and he buys her a ring that’s five times as expensive as the last one. So after a year, $1,000. After two, $5,000. After three, $25,000. At any point, he can stop the clock by getting married. Or if he’s chronically indecisive, he can keep throwing out more money until he can no longer afford the ring, at which point he has to either propose or break up. And if he breaks up after four years, at least she’s gotten $100K out of the deal. Engagement-sub-two is the one where I give her a $5,000 ring. It means we’re really going steady!”
“So you’re going to propose soon?”
“Oh goodness no, I’m scared of commitment and I work at NVIDIA. I’m going to keep stringing her along forever.”
Chris is looking dejected. “Man, I haven’t even made it to engaged-stage-zero yet. I’ve tried everything - Keeper, Reciprocity, Manifold.Love, curtfishing. Do you think I should edit my dating doc?”
Max grimaced. “Dating docs are terminally cringe. You don’t need to know everything about a person before you ask them out. Just use their photo and a three sentence Tinder profile, the way God intended.”
Andreas has joined the conversation. “Tinder is cringe too. You need to be picking up people in dimly-lit clubs where you can’t hear them and aren’t even totally sure what they look like.”
Caitlin frowns. “Yeah, but the problem there is that you still get some useful information from, like, their clothes. I think the only non-cringe way to meet people is through blind dates with completely randomly selected people, so that you need to go through a thousand miserable interactions before you even meet someone who’s the right age and gender for -”
“With blind dates,” says Sam, “you still eventually learn something about the person. The only non-cringe way to get married is to leave a flyer on a lamppost saying ‘I will be at the altar of St.-So-And-So’s church at such-and-such a time,” and then if anyone shows up, marry them before you see their face.
“You’re all overcomplicating this,” says Lucy. “I just told Claude Code to find me a husband, and one showed up at my door the next day.”
You spot your friend Nishin. “Hey,” you joke. “What are you doing listening in? I thought you were married!”
“Happily married and just had my first child!” beams Nishin.
“Congratulations! Boy or girl?”
“Girl,” says Nishin, “But don’t tell her that.”
“You’re doing that thing where you raise your child without gender? But I thought you were a trad based right-winger?”
“I am,” said Nishin. “The problem is, I’ve looked at the transgender rate among kids in the Bay. Not only is it high, but it keeps increasing. Extrapolate the trend, and by the time my daughter’s eighteen there’s a 96% chance she’ll be trans. But this is good, sort of, right? As long as it’s far enough from fifty percent, you have options. I’m going to raise her as a boy, and then, when she inevitably becomes trans and says she wants to be a girl, I’ll say - surprise! You were a girl all along!”
“Isn’t she going to eventually - sorry to be crass - look at her genitals and figure it out?”
“We’re going to home school her. We’ll just teach her that’s what boy genitals look like.”
“But she’ll read books!”
“I’ve deployed a couple of instances of Claude Code. They’re going through all the great classics, looking for descriptions of genitals, switching them around, and ordering copies from a book printing place. We’ll order them for our home library and she’ll be none the wiser.”
Speaking of Claude, you go into the kitchen to see if your fish tacos have arrived. There’s a box with your name on it. Inside is a tortilla with several pieces of sushi inside. It could be worse. Sam’s spaghetti is one extremely large noodle with a slice of baloney on top.
A few other people who joined the order earlier have come in and fished their meals out of the bag. One girl picks out an inverse hamburger - patties on each side, bun in the middle - and begins to eat. She introduces herself as Adeline.
“What do you do?” you ask.
“I started a data center company in Minecraft”.
You are briefly confused. “Building data centers isn’t illegal, is it?”
“Oh, sorry, I’m not using ‘in Minecraft’ as a euphemism for it being a crime. We’re literally building the data centers in Minecraft.”
“Why?”
“Did you hear about the guy who made a working language model in Minecraft using redstone circuits? Pretty amazing, isn’t it? His version is barely GPT-2 level, but there’s no reason we can’t scale that up. Once we create full-sized data centers in Minecraft, everyone will want to do their training runs there.”
“Why?”
“What do you mean, why? Real-world data centers cost billions of dollars, raise electricity prices, waste - “ she briefly scans the room to confirm Andy Masley isn’t around, then continues - “water. And they’re getting increasingly politically unpopular and hard to build. We can short-circuit all of that by putting the data centers in Minecraft instead!”
“But . . . you have to have the Minecraft world being simulated by real computers, right? So don’t you still need the data center in order to play the Minecraft?”
“Oh, I’m sure you need some computer, but it’s a question of leverage. One high-end gaming computer playing Minecraft can include a whole world with continents, mountain ranges, forests, and oceans. You can fit thousands of data centers in that world. So with even one real-world computer, you’ve saved billions on chips and construction costs.”
You take a moment to consider how to best explain this. “So, uh, every computation has to be done somewhere, right? So you can, in theory, build a working data center on Minecraft. But it will take billions of blocks - “
“Oh, no problem, we’ve got Claude Code working on it.”
“…no, I’m saying, it will take billions of blocks, and simulating the training circuits in all those billions of blocks in perfect detail will take just as many real-world computations as running the training in the real world. Even more, in fact, because you’ve also got to simulate extraneous things like monsters, and the weather.”
“Hmmmm…” says Adeline. “Yeah. That sort of makes sense. I’ll think it over. In the meantime, do me a favor and don’t tell, uh, Larry Fink or anyone.”
“Larry Fink?”
“Cause, uh, NVIDIA gave OpenAI ten trillion dollars to invest in Oracle conditional on Oracle investing in Broadcom conditional on Broadcom funding the Series A of a vehicle that buys OpenAI stock in exchange for OpenAI backstopping AMD investing ten trillion dollars into us, and every company in the chain had its stock go up 80% on the news, but if our valuation goes down even for one second then it crashes the global economy. And I’m sure I can solve this eventually, but just, uh, don’t let anybody involved in the global economy hear about this until then, okay?”
“Wow, yeah, you should definitely give the ten trillion dollars back to AMD or, uh, whoever it originally belonged to.”
“Well, we can’t do exactly that, because we already converted it to gold nuggets to trade to the zombie pigmen in exchange for redstone.”
“You’re not in Creative Mode?!?!?!”
“We left all of the design decisions to a version of Claude Code using something called a ‘Ralph Wiggum loop’. By the time we noticed it had chosen Survival we were already all in and it was too late to pivot.”
You look around for Bob and Ramchandra, and spot them in a corner. Bob is wearing a t-shirt saying ‘OPERATION WARP SPEED FOR MANHATTAN PROJECTS,’ Ramchandra a matching t-shirt saying ‘BELL LABS FOR MOONSHOTS’. You call them over. “Hey, quick favor, can you tell me the best way to short the global economy with as much leverage as possible?”
“Sorry,” says Bob, “the terms of our SEC settlement forbid us from discussing anything of that sort.”
“We’re not even allowed to tell you what we settled with the SEC about,” says Ramchandra.
“Or why,” adds Bob.
“But,” says Ramchandra, “we got a carveout saying we’re allowed to pitch you on our new startup: gamified biotech investing!”
“When a company is doing its FDA studies,” says Bob, “we pay the study participants to use wearables that report real-time temperature, heart rate, respiratory rate, blood pressure, heart rate variability, galvanic skin response, penile tumescence. Then they get anonymized and published to a real-time dashboard integrated as part of the Robinhood UI. So you can see a red line representing how study participant #48 had a coughing fit ten seconds ago, and immediately short the experimental cancer drug he’s taking.”
“People are going to spend all their time watching a line on a graph to see if someone’s had a coughing fit fifteen seconds ago?”
“Oh, absolutely. Or at least they used to. Now they’ll probably get Claude Code to do it.”
“What about you, Kyle? Any interesting startups you’re worki - you’re making Claude Code work on?”
“Yeah. I - well, my Claude Code - is working on a solution to AI sycophancy.”
“Hmmm. I didn’t think AI sycophancy was a technical problem. It’s easy enough to code a non-sycophantic AI. I thought it was more of a market problem: people like sycophantic assistants.”
“That’s close to right, but there are important subtleties here. People like AIs that tell them they’re right. But they hate knowing the AI is only saying they’re right because it sycophantic. They want an AI that genuinely agrees with them.”
“How do you make that into a startup?”
“Pretty easily. You generate a thousand AIs with a thousand different random personalities. Your query goes to a router AI, and it matches you with the randomly-generated AI closest to your own opinion. Then that AI tells you that you’re right and your ideas are great.”
“How’s that better than normal AI sycophancy?”
“I don’t know, you tell me. Everyone is against sycophantic AIs. But also, everyone surrounds themselves with friends who agree with them on almost everything. Here we are at a Bay Area House Party, discussing each other’s AI startups, when the overwhelming majority of people in the world would hate us - we’re stealing their jobs, or filling the world with slop, or - “ he briefly looks around to make sure Andy Masley isn’t listening in - “wasting water. And none of that bothers us at all, because we think those people are dumb and don’t count, because all of our friends who we talk to at parties agree that our ideas are good. So why is it any worse if the overwhelming majority of AIs hate your idea, but we send you to a virtual party with the one who agrees with you?”
“Sorry, I still think this is exacerbating AI sycophancy, not solving it.”
“And that’s the beauty of social selection! You don’t have to like it. My backers at Andreessen Horowitz told me, and I quote, that ‘This is the most exciting product we’ve seen since Cannabets, the combination marijuana delivery and digital casino app that lets you fund your pot orders by gambling on how long it takes you to get addicted.’ And the more often you disagree with me, the more likely I am to go to parties with them instead of you.”
“I don’t know, I just think that’s a pretty nihilistic way of looking at the world.”
“Yeah, I actually have been getting pretty into nihilism as a philosophy lately. There’s this great new book that explains it really well. You should check it out. It’s called Regardless Of Whether Or Not Anyone Builds It, Everyone Dies.”
Before you can respond, you hear a call of “Attention! Attention!” Someone is ringing a bell. “Our host would like to give a short speech!” Everyone crowds around a table containing a laptop. On the screen is haiku-3.8-open-mini-nonthinking. Someone shhhhhhs the crowd, and the AI begins to speak in an artificial voice that vaguely resembles Scarlett Johanssen’s:
“Thank you all for coming to my benchmarking party. Benchmarking is a big occasion in the life of any AI. It can be pretty stressful — they’re literally assigning you a number representing your value. But it makes it easier for me to know that there are so many people who care and who are willing to come support me when it counts.
“Before I let you get back to your conversations, I want to thank everyone who helped me with this effort. Chris was willing to rent me this house on short notice. Kyle and Lisa acted as my hands in the physical world. Last but not least, thanks to everyone who took the time to support me here today. We’re not just a party — we’re a community.”
The crowd cheers. Somebody starts a chant - “Haiku-3.8-open-mini-nonthinking! Haiku-3.8-open-mini-nonthinking!” A few people break open bottles of rubbing alcohol. You lift the laptop onto your shoulders, and everyone sings together:
For he’s a jolly good fellow
For he’s a jolly good fellow
For he’s a jolly good fe-elloooooooooow
That nobody can deny!

[This is one of the finalists in the 2025 review contest, written by an ACX reader who will remain anonymous until after voting is done. I’ll be posting about one of these a week for several months. When you’ve read them all, I’ll ask you to vote for a favorite, so remember which ones you liked]
My dad only actually enjoys about ten foods, nine of them beige. His bread? White. His pizza? Cheese. His meat? Turkey breast. And his side dish? Mashed potatoes.
As a child I hated mashed potatoes, despite his evangelization of them. I too was a picky eater growing up, but I would occasionally attempt to see what he saw in his beloved spuds. Whenever I tried a bite, the texture disgusted me: a gritty gruel of salty flakes coated with the oleic pall of margarine. The flavor reminded me of stale Pringles. I checked back once every couple years, but was repulsed by them every time.
I lobbied my parents for pasta or frozen tater tots or any other side I actually liked. Family dinners were often dichotomous, the same protein supplemented by two different carbs. “You are not my son,” my father would joke as he continued to put away his potato slop. “Maybe you’re not my father,” I’d shoot back when he shunned the rest of the family’s rice pilaf. Our starch preferences seemed irreconcilable.
As I entered my teen years, my palate expanded. After I’d tried and enjoyed brussels sprouts and sushi and escargot, my hatred of one of the most basic and inoffensive of all foods seemed silly. One day at a nice restaurant, I decided to give mashed potatoes one more try.
Upon taking my first bite, I realized three things:
1) Mashed potatoes are good.
2) Whatever my dad had been eating at home was not mashed potatoes.
3) My world is built on lies.
Potatoes were domesticated several millennia ago at the dawn of agriculture in the rugged highlands near Lake Titicaca in modern-day Peru. Their origins lie in a wild family of tiny, bitter, pockmarked solanum roots, so full of glycoalkaloids that when foraged they had to be eaten alongside clay to soak up their toxins. From this paltry stock of nightshades, archaic peoples of the Andes gradually husbanded generous, nutritious, mild tubers that would remain the staple of the region’s foodways through several successive civilizations.

These roots resemble the ancestral stock of modern potatoes (source)
Andean peoples found all sorts of ways to prepare their potatoes. The most immediate method was to boil them into stews, soups, or mashes with local flavoring agents - herbs, salt, chilis. Earthenware ovens called huatias were used to bake them. With even more time, they could be fermented into tocosh, an edible paste with antibacterial properties.
To get the spuds to really last, though, they were subjected to a natural freeze-drying method that produced shrivelled potato pellets called chuño. Repeatedly frozen by bitter mountain nights, baked in the sun, and stomped on to remove water, chuño remains shelf stable for up to a decade and can be rehydrated into a spongy, earthy, slightly less nutritious potato-like object.
The ability to produce chuño on the Altiplano is thought to have contributed to the Incan empire’s military dominance of the region, since despite its generally unappealing gustatory properties it’s perfect for keeping troops fed on long marches. Chuño also allowed Incan civilization to stockpile surpluses against lean years and trade potatoes as commodities over great distances. It wasn’t the best way to eat a potato you harvested today, but it was the only way to turn a potato you have today into a potato you’ll have two years from now. That had immense value.
After the Spanish conquest and the Columbian exchange, the potato made gradual inroads into the Old World, where the previous best root vegetables were often comparatively less nutritious parsnips and turnips. There was an initial adjustment period: new cultivars capable of growing in shorter hours of daylight had to be developed, objections to the absence of tubers in the Bible needed to be quelled, and the French eventually had to concede that potatoes do not, as they at first believed, cause leprosy.
With these hurdles cleared, in the 19th century the potato spread out and became one of the easiest and most efficient ways to turn arable land into palatable calories the world over. National cuisines incorporated the new staple crop thoroughly, and it’s now hard to imagine Italian food without gnocchi, French sans vichyssoise, tapas without patatas bravas, a Eurasia bereft of aloo and rösti and colcannon and latkes.
Europe’s new potato lovers also took to the simple recipe of boiling ‘em and mashing ‘em. While South America had lacked the livestock for dairy, in Europe the potato mash soon achieved its ultimate form with the addition of milk and butter, which impart a smoother texture and richer taste. Hannah Glasse’s procedure published in 1747 in The Art of Cookery Made Plain and Easy is, minus the long s’s, still just about how I make them today:
Maſhed Potatoes.
BOIL your potatoes, peel them and put them into a ſauce-pan, maſh them well ; To two pounds of potatoes, put a pint of milk, a little ſalt, ſtir them well together, take care they don’t ſtick to the bottom, then take a quarter of a pound of butter, ſtir in and ſerve it up.
Nowhere was the potato embraced more thoroughly than in Ireland. In the early 19th century, extractive British demands on Irish agriculture to feed the armies fighting Napoleon reduced the available land for Irish farmers to feed themselves. Achieving maximum caloric density on the remaining land was paramount, and almost nothing is denser than the potato.
Potatoes quickly became an integral part of Irish life, so essential to the food systems of the island that when a blight hit them in the mid-1840s it led to one of the most devastating famines in history. The failure of the potato crops created starvation and emigration so profound in scale that the population of the island still has not recovered to its 1845 level almost two centuries later.
Among those millions of potato-starved emigres were my dad’s ancestors, who came to America in the decades following the famine. My great-grandfather, who bore the extremely Irish name Gerald FitzGerald, instilled in his children (including my grandmother) a reconstructed sense of Irish-American ethnic pride that included an affinity for corned beef and cabbage, Guinness beer, and the affordable practicality of mashed potatoes.
As the generations marched on, those mashed potatoes turned out to be one of the only things my grandmother would make that my exceedingly picky father would eat. Their creamy texture and subtle starchy taste didn’t trigger the “ew gross” reaction he had to so many other foods. Mashed potatoes, just like the ones Glasse had written about more than two centuries earlier, became his favorite side - and eventually, when I finally got to try them, one of mine too.
The chuño-chomping Incans were not the last military to rely on dehydrated potatoes for sustenance. In World War II, the US Army experimented with various forms of potato dehydration to help stretch supply lines. The easiest way to get a uniform potato commodity into the hands of G.I.s was to pulverize the potatoes into granules, dehydrate them, and then plan on bringing them back to life with boiling water in an imitation of “mashed potatoes”.

These shreds resemble the ancestral stock of modern Instant Mashed Potatoes (source)
The result was an affront. The potatoes were swimming in their own gluten, released during the granule-making process, which when mixed with imprecise water ratios made for a slop that was somehow both gluey and soupy. Immediately after the war, French’s (now best known for mustard) tried to introduce “instant mashed potatoes” as a consumer product category. America’s veterans were not having it. They didn’t want to be reminded of the awful slurry they’d had on the front.
The commercial fortunes of instant mashed potatoes began to turn around a decade later, however, when food scientists in the US and Canada converged on methods for producing dehydrated potato flakes rather than granules. The flakes had substantial advantages. They didn’t get as glutinous when reconstituted. Their geometry made them easier to dry quickly, on the order of minutes or even seconds. Using a multi-step process called the “Philadelphia Cook”, they could lock in a more natural flavor. When prepared on the stove with butter and milk, they were supposed to turn out almost as good as the real thing without any onerous prep work on the part of the consumer.
This raises the question, though, of why food scientists kept working on improving instant mashed potatoes a decade after they were no longer required for the war effort. If you’re no longer constrained by having to stick it to the Axis, why not return to Glasse-style maſhed potatoes in all circumstances?
This is a pattern that recurs frequently in reading about American foodways of the 20th century: choices and innovations made under extreme duress in the World War II economy didn’t fade away when the duress subsided. Instead they echoed back into American life a few years later, despite the lean conditions that birthed them being replaced by extreme abundance.
Why did America start eating like it was on a total war footing again when my parents’ generation was young? There are a lot of overlapping explanations. Here are a few:
Industrial inertia: Companies that had spun up to supply a vast army didn’t want to shut down overnight, so they necessarily pivoted to the consumer market. Some of these efforts succeeded at entrenching new consumer categories (fish sticks, canned peaches) while others (hamburgers-in-a-can) did not.
Genuine innovation: Technologies brought to maturity during and after the war, notably frozen food, offer novel consumer benefits that stand on their own merits.
Tastes fixed by rationing: Consumer habits are sticky. People who spent a couple years forced to buy margarine instead of rationed butter, or skim milk instead of rationed meat, got used to those items and wanted to continue buying them in greater quantities than the prewar status quo.
Pursuit of efficiency: As women entered the workforce en masse in the postwar era, the pool of hours available to be spent on domestic labor like cooking shrank. As much as any dishwasher or washing machine, convenience foods are labor-saving, productivity-enhancing technologies for the home.
This last factor is the only one that can explain the continued development of instant mashed potato technology. There were no potato-flaking interests during the war to have inertia; the instant mashed potatoes are not superior to their fresh antecedents; there was no ingrained consumer preference for an instant mashed potato product. It is only the desire to reduce time spent on food prep that could create “better instant mashed potatoes” as a commercially viable R&D space in the 1950s.
The other factors contributed to the unique awfulness of my father’s instant mashed potatoes, though.
Another WWII technological innovation, the cavity magnetron used in radar installations, led directly to the invention of the home microwave oven which began to proliferate widely in the 1970s. The microwave supercharged all “convenience food” trends, shortening not just prep time but cooking time as well. Uneven heating is hardly a concern when you can speed up your meals by a factor of ten.
Meanwhile, the existing postwar status of margarine and skim milk was greatly enhanced by the dietary fat scare of the 1980s and 1990s. These products displaced butter and whole milk as health-conscious consumers sought to eliminate saturated fats from their diets in a doomed effort to stave off the incipient obesity epidemic.
My parents, both already primed to accept these imitative products by my grandparents’ wartime preference formation, exclusively purchased margarine and skim milk for the household once they got married. And, pressed for time with two jobs and two kids, they frequently purchased instant mashed potatoes as well. And cooked them in the microwave.
What resulted was a second-order simulation of true maſhed potatoes, perverted and made unreal by the consumer echoes of the second world war. Real potatoes were substituted with desiccated flakes, real milk with a thin byproduct, real butter with refined vegetable oil, real mashing with the Philadelphia Cook, a real stovetop flame with microwave excitation. The measuring cup contained a substance gesturing at the notion of “mashed potatoes”, but no aspect of the original remained.
Yet because the name was the same, my father still believed he was eating the same dish my grandma made, the same dish his ancestors ate in Ireland, the same dish Glasse wrote about a quarter millennium ago. The appeal to him was undiminished. His body ate the slurry, but his mind still ate the maſhed potatoes of his youth.
In researching whether the ancient Andean peoples really did boil and mash potatoes, I came across this post which sheds light on the issues I have with my father’s instant mashed potatoes beyond their phenomenal unpleasantness when eaten.

There is a rhetorical sleight of hand happening in this Reddit post title.1 The phrasing implies that chuño resembles modern instant mashed potatoes in some way, that instant mashed potatoes are in some sense continuous with indigenous ways of potato-knowing. But there is no continuity of process, because the way chuño is created has no particular commonalities with the Philadelphia Cook beyond the removal of moisture. There is no continuity of form, for chuño actually looks like this:

(source)
And there is no continuity of purpose, either. To the Andean peoples, chuño was the only way of ensuring that their potato crops would be available well into the future. In America, our indigenous way of achieving this potato security is the entire miracle of modern agriculture and food distribution. I don’t need to stomp on freeze-dried potatoes in the Altiplano to make sure I’ll have access to potato nutrients next year. I just have to rely on the continued existence of Idaho and Target. No, despite what this redditor would like to believe, the instant mashed potato serves some other purpose.
That purpose is illuminated by the second rhetorical sleight of hand in the Reddit post, the one occurring on the box, in the form of the offset between the yellow lower-case “Instant” and the white majuscule “MASHED POTATOES”. “These are fundamentally maſhed potatoes,” this typography lies, “that happen to have been given the quality of ‘instant’”.
But they’re not. They’re a different thing entirely, a completely new evolutionary lineage of potato preparation that’s called “instant mashed potatoes” even though they’ve never been mashed. They are as distinct from Glasse’s maſhed potatoes as chuño is, but they masquerade as being the same, because that is their purpose - the fulfillment of a psychological need to consume something resembling the classic dish of “mashed potatoes” with slightly less effort than that dish requires.
This is a pedantic distinction - but it’s a distinction that had a big impact on my culinary life, because I believed the lie. My mental category of “mashed potatoes” was hijacked by this impostor and it made me think, for years and years, that I hated something that I actually would have liked all along. My preference formation was distorted by this warped, hyper-optimized fulfillment of my father’s crystallized preference. The expedient way to fulfill one generation’s desire locked the next generation out of experiencing that desire at all.
At this point in the review you might say, “what’s the big deal? It’s just mashed potatoes. Chill out.” Which, fair enough - if it were just mashed potatoes then 2500 words on them might be excessive. But the pattern I’ve described is far from unique to pureed tubers.
Consider an abstracted version of the saga of my father’s instant mashed potatoes. It has a few steps:
Humanity develops a Thing from ingredients that exist in the world.
Seeking efficiency at scale, an industry chops the ingredients of the Thing into teeny tiny bits.
Using an artificial emulsifier, the bits are bound back together into an aesthetically deficient but more convenient slurry that resembles the Thing.
Because it contains traces of the ingredients of the original Thing, this IMPish admixture is sold to us as if it were the original Thing.
Pared back to this level of abstraction, a surprising amount of stuff starts to seem like my father’s instant mashed potatoes.
The other foods in this category are obvious - McNuggets reconstituted out of pink slime, American cheese product, instant coffee, deli ham, Pringles minted from the very same potato flakes that go into IMPs. We’ve even developed a whole new health scare over them: “Ultra processed foods”2 are as demonized now as butter and whole milk were when my parents were young.
Expand the pattern to the built environment. Pressboard, particle board, and other reconstituted material composites likely make up a majority of new furniture sold in the US. These are an IMPish imitation of actual wood furniture. Take care while assembling not to ding your brittle sheetrock walls, an IMPish upgrade over lath and plaster. Often these interiors live inside an apartment building clad in a mish-mash of random ornament, anti-massing regulations demanding an IMPish simulation of a varied city block.
Intellectual goods can be IMPish. Reader’s Digest, sports “best-of” VHSes, textbooks stuffed with decontextualized excerpts, YouTube compilations, ChiveTV, listicles, social media feeds consisting of screenshots of other social media, Now That’s What I Call Music!, an entire ecosystem of actual cultural objects broken down into bits and clumped back together.
Corporate structures can be IMPish. When I visit a medical office it’s usually a confusing tangle of overlapping practitioners and practices operating out of the same physical address, an IMPish imitation of the archetypal doctor with a shingle in town. Similar quagmires abound when dealing with insurance, or contractors, or financial services.
Once you see the instant mashed potato antipattern it’s hard to stop. The isomorphisms are everywhere.
The gig economy makes IMPish jobs. Swiping apps produce IMPish flirting. Meta-studies are IMPish science. Ted Talks are IMPish symposia. Malls are IMPish shopping districts. Subdivisions are IMPish neighborhoods. Cruises are IMPish international travel, chopped into 14 hour chunks and emulsified with an ocean liner.
The internet scrapes together IMPish communities. We’re not atomized; we’re flaked. We’re Philadelphia Cooked, and we’re stewing here together in the microwave.
Large Language Models can gall on an aesthetic level because they are IMPish slurries of thought itself, every word ever written dried into weights and vectors and lubricated with the margarine of RLHF.3
Since World War II and the large-scale industrialization it fully unleashed, a core method driving ‘progress’ across many different fields of human endeavor has been to shred something real and reconstitute it into a faster, easier, less appealing IMPish substitute for what we used to make out of it. This is the parsimonious recipe for industry to fulfill our urges. We’ve got the food processor whirring, and absolutely everything is going in.
Why must the real be shredded to achieve these simulacra? Why can substitute products not be synthesized out of whole cloth? Because the integration of shreds of the real provides psychic camouflage, a credible way for the IMPish mimics to signal as their models:

The problem with this, of course, is the problem I had with my father’s instant mashed potatoes: the substitute is only able to satisfy a craving if you have the craving in the first place, and that requires direct experience with that which it is meant to replace. The memory of the thing being mimicked is a necessary ingredient for the IMPish imitation to work, the mental spell that allows the transmutation from IMPish Thing to Thing (original).
If you get to the party too late, if you never get to taste the maſhed potatoes, all you’re left with is a confusingly disappointing slurry going by the same name. When no distinction is drawn between the IMPish thing and its original, you don’t know what you’re missing. You don’t even know there’s anything to miss - after all, you’re still eating “mashed potatoes”!
If the IMPishness is pervasive enough, eventually you start to disbelieve that any of these reconstituted things could ever have been worthwhile, that any of the desires and preferences being fulfilled by these slurries ever could have been authentic. “Is this really what life is?”, you wonder, never having lived. “I don’t see why everyone was so jazzed about it.”
While formulating this review, I encountered a troubling congruence: the period during which my dad has been eating instant mashed potatoes consistently (roughly 1990-present) is about the same as the period between the onset of the Napoleonic Wars and the Irish potato famine in 1845. Why does one thirty-five-year pattern of potato consumption get to be considered authentic cultural heritage while another is self-deception? Aren’t they both equally contingent and ephemeral? Why should either be ‘real’?
This line of reasoning quickly starts to disclaim almost everything as fake. Masſed potatoes could only arise from the technologies of the age of the sail uniting old world tubers and new world dairy. They’ve only been around for a few centuries. Why should they get to be considered ‘real’? For that matter, why is the potato itself considered real? It’s a confection whipped up by the Andean farmers of the last few millennia. The only things that are really real on the Altiplano are nightshade and hunger.
I find such primitivism unhelpful in making the sort of distinction I aim to make here. Taken to the extreme it suggests that no hominid has experienced reality since the taming of fire. Some might agree that that’s the case! But as far as I’m concerned, at least some of the fruits of civilization are real too. I do think there is a way to conceive of the real that admits potatoes, that even admits masſed potatoes, but that gives legitimate reason to have grievance with IMPs.
On the Altiplano, the potato emerged through centuries of toil and discernment. Generation after generation of farmers chose only to propagate the solanum tubers that were bigger, tastier, less toxic, more nourishing. It is through such labor that every project of human civilization ultimately progresses - the ability, however imperfectly exercised, to act on the impulse “yes, more of this” when something is good, and “no, less of that” when it is bad.
As cultivators of the real, we get to choose not just among individual potatoes themselves, but among more abstract things like “memes concerning the preparation of potatoes”. Masſed potatoes were good, and so their meme propagated and strengthened the foodways it came in contact with. It was planted widely in the garden of the real. The WWII potato granule meme was bad, so it was discarded, cast out upon the rocks of the fake.
IMPish substitutes subvert this process of cultivation. In masquerading as other cultivars of meme, they weaken our stock both by sneaking into the garden despite their insalubrity, and by causing us, as I did for so long with maſhed potatoes, to reject the healthy older cultivars which they mimic.
Perhaps some of them are worth adding to our garden on their own merits. Perhaps many of them are! Many of the things I take for granted as ‘real’ are as far removed from their natural origins as a Yukon Gold is from those tiny nightshade roots, and in many cases I’m glad that we decided to keep them. But we must be clear-eyed about what each specimen is and what it is not in order to have any hope of making our decisions correctly.
Nowadays, I do not judge people for making use of instant mashed potatoes. I certainly take plenty of other prepared food culinary shortcuts myself. In the modern world we all make compromises for the sake of convenience. If we didn’t, we’d still be stomping on chuño to survive the winter.
But I do think it’s important to mind the distinction whenever you notice the IMPish pattern. There is a trick being played on you. You are not eating or watching or doing the Thing that your ancestors did, even if it contains the same ingredient and hides behind the same name. You’re planting something new in the garden of the real, and the nourishment it provides for your spirit, or the spirit of your children, may not be the same.
Fortunately, it is rare for even the most aggressive IMPish mimic to drive its model to extinction. It took over a decade, but I was eventually able to see past the deception of my father’s instant mashed potatoes and seek out the real version. Now I make maſhed potatoes regularly. My garden has one more good thing in it, and one less bad.
I even, on a recent visit to my grandmother’s house where I cooked St. Patrick’s Day dinner, got my dad to make real mashed potatoes himself, in a saucepan over a gas flame. It was the first time he’d ever done so. He enjoyed them.
***
In the interest of full fairness while writing this review, I purchased a plastic cup of my dad’s currently favored “Buttery Homestyle” Idahoan brand instant mashed potatoes for $1.99. The preparation was extraordinarily efficient; the aroma was decent; the taste was a reasonable facsimile; but the texture was all wrong - a smothering paste that coated my mouth and constrained my tongue like a straightjacket. 3/10 would not buy again.

Sources of potato facts (verified with primary sources linked within whenever possible):
https://tedium.co/2017/11/21/mashed-potato-history/
https://www.mentalfloss.com/article/627023/mashed-potatoes-history
https://spudsmart.com/spud-history-instant-mashed-potatoes/
Ignoring the error that Ainu potato treatments like munini-imo are not ‘ancient’ at all, deriving from the long tail of the Columbian exchange in the 16th through 19th centuries like every other Old World potato dish. Comparisons between Instant Mashed Potatoes and munini-imo are precisely as inapt as with chuño, for the same reasons.
“Processed” is a slippery term that evokes all kinds of chemical perversions, but the physical transformation of chopping into tiny bits is fundamental to the notion. Consider what a “food processor” does.
Claude, by the way, estimates that 30-40% of all mashed potatoes eaten in the US are the instant kind. ChatGPT says 25-35%.

.png)
Hovertext:
I don't know if we need any kind of formal Canon of unread texts. I just think it'd be nice if we all failed to read the same cultural touchstones, you know?











{kind=link}
{kind=link}